数据一致性问题
# Java 操作 Redis
# Jedis的基本使用
java连接Redis
#首先查看linux的防火墙状态
>sudo ufw status
#查看系统哪些端口开放了
>firewall-cmd --list-ports
#开启端口:6379
>firewall-cmd --zone=public --add-port=6379/tcp --permanent
#重新启动防火墙
>firewall-cmd --reload
#查看系统哪些端口开放了
>firewall-cmd --list-ports
public void t1(){
String host="192.168.110.128";// 192.168.110.128 172.17.43.122
int post=6379;
Jedis jedis=new Jedis(host,post);
jedis.auth("123456");
jedis.set("strName","zhangsan");
String stringname=jedis.get("strName");
System.out.println(stringname);
jedis.close();
}
# Jedis工具类
@Test
public void t3(){
JedisPoolConfig jedisPoolConfig=new JedisPoolConfig();
jedisPoolConfig.setMaxIdle(5);//最大空闲数
jedisPoolConfig.setMaxTotal(100);//最大连接数
String host="192.168.110.128";// 192.168.110.128 172.17.43.122
int post=6379;
JedisPool jedisPool=new JedisPool(jedisPoolConfig,host,post);
Jedis jedis=jedisPool.getResource();
jedis.auth("123456");
System.out.println(jedis.ping());
jedis.close();
}
# Jedis对Hash类型的操作
# Spring-Data 整合 Redis
# string 案例限制登录功能
- 判断当前登录的用户是否被限制登录
- 如果没有被限制(执行登录功能)
- 如果被限制做相应提示
- 判断是否登录成功
- 登录成功--》(清除输入密码错误次数信息)
- 登录不成功
- 记录登录错误次数
(判断 Redis中的登录次数KEY是否存在)user:loginCount:fail:用户名
- 如果不存在,是第一次登录,设置失败次数为1。user:loginCount:fail:用户名进行赋值,同时设置失效期
- 如果存在,查询登录失败次数的key结果
if(结果<4)
user:loginCount:fail:+1
else{//4
限制登录KEY存在,同时设置限制登录时间锁定1小时。
}
# hash 类型案例
# spring-boot整合redis
配置文件:application.properties
spring.datasource.url=jdbc:mysql://39.96.88.215:3306/mybatis
spring.datasource.username=root
spring.datasource.password=123456
#spring.datasource.driver-class-name=com.mysql.jdbc.Driver
#开启驼峰命名
mybatis.configuration.map-underscore-to-camel-case=true
#打印日志
logging.level.com.walegarrett.springbootcache.mapper=debug
#debug=true
spring.redis.host=39.96.88.215
spring.redis.password=123456
spring.redis.port=6379
RedisConfig
@Configuration
public class MyRedisConfig {
@Bean
public RedisTemplate<Object, Employee> empRedisTemplate(
RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
RedisTemplate<Object, Employee> template = new RedisTemplate<Object, Employee>();
template.setConnectionFactory(redisConnectionFactory);
//转换为json保存
Jackson2JsonRedisSerializer<Employee> ser = new Jackson2JsonRedisSerializer<Employee>(Employee.class);
//设置默认序列化器
template.setDefaultSerializer(ser);
return template;
}
@Bean
public RedisTemplate<Object, Department> deptRedisTemplate(
RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
RedisTemplate<Object, Department> template = new RedisTemplate<Object, Department>();
template.setConnectionFactory(redisConnectionFactory);
Jackson2JsonRedisSerializer<Department> ser = new Jackson2JsonRedisSerializer<Department>(Department.class);
template.setDefaultSerializer(ser);
return template;
}
}
序列化和保存对象
@Autowired
EmployeeMapper employeeMapper;
@Autowired
StringRedisTemplate stringRedisTemplate;//k-v都是字符串
@Autowired
RedisTemplate redisTemplate;//k-v都是对象
@Autowired
RedisTemplate<Object,Employee> empRedisTemplate;
@Test
public void test02(){
//默认如果保存对象,使用jdk序列化机制保存
Employee employee=employeeMapper.getEmpById(1);
//redisTemplate.opsForValue().set("emp-01",employee);
//将数据以json的形式保存:
// (1)自己将对象转换为json
//(2)修改jdk的默认序列化机制
empRedisTemplate.opsForValue().set("emp-01",employee);
}
# Redis与数据库数据不一致问题
# 问题背景
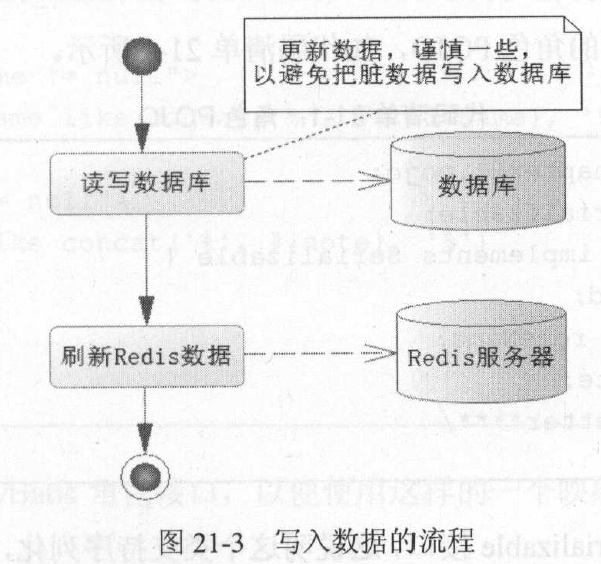
假设两个业务逻辑都是在操作数据库的同一条记录,而Redis 和数据库不一致,如图21-1 的场景。在图21-1 中, Tl 时刻以键keyl 保存数据到Redis, T2 时刻刷新进入数据库,但是T3时刻发生了其他业务需要改变数据库同一条记录的数据,但是采用了key2 保存到Redis 中,然后又写入了更新数据到数据库中,此时在Redis 中keyl 的数据是脏数据,和数据库的数据并不一致。
不用沮丧,因为互联网系统显示给用户的信息往往并不需要完全是“最新的”,有些数据允许延迟。举个例子, 一个购物网站会有一个用户购买排名榜,如果做成实时的,每一笔投资都会引发重新计算, 那么网站的性能就存在极大的压力,但是这个排名榜却没有太大的意义。同样, 商品的总数有时候只需要去实现一个非实时的数据。这些在互联网系统中也是十分常见的, 一般而言,可以在某段时间进行刷新(比如以一个小时为刷新间隔),排出这段时间的最新排名, 这就是延迟性的更新。
但是对于一些内容则需要最新的,尤其是当前用户的交易记录、购买时商品的数量, 这些需要实时处理,以避免数据的不一致,因为这些都是对于企业和用户重要的记录。我们会考虑读/写以数据库的最新记录为主,并且同步写入Redis,这样数据就能保持一致性了, 而对于一些常用的只需要显示的,则以查询Redis 为主。这样网站的性能就很高了, 毕竟写入的次数远比查询的次数要少得多得多。下面先对数据库的读/写操作进行基本阐述。
写操作要考虑数据一致的问题,尤其是那些重要的业务数据,所以首先应该考虑从数据库中读取最新的数据,然后对数据进行操作,最后把数据写入Redis 缓存中。
# 解决方案
那么我们这里列出来所有策略,并且讨论他们优劣性。
- 先更新数据库,后更新缓存
- 先更新数据库,后删除缓存
- 先更新缓存,后更新数据库
- 先删除缓存,后更新数据库
# 先更新数据库,后更新缓存
这种场景一般是没有人使用的,主要原因是在更新缓存那一步,为什么呢?因为有的业务需求缓存中存在的值并不是直接从数据库中查出来的,有的是需要经过一系列计算来的缓存值,那么这时候后你要更新缓存的话其实代价是很高的。如果此时有大量的对数据库进行写数据的请求,但是读请求并不多,那么此时如果每次写请求都更新一下缓存,那么性能损耗是非常大的。
举个例子比如在数据库中有一个值为 1 的值,此时我们有 10 个请求对其每次加一的操作,但是这期间并没有读操作进来,如果用了先更新数据库的办法,那么此时就会有十个请求对缓存进行更新,会有大量的冷数据产生,如果我们不更新缓存而是删除缓存,那么在有读请求来的时候那么就会只更新缓存一次。
# 先更新缓存,后更新数据库
这一种情况应该不需要我们考虑了吧,和第一种情况是一样的。
# 先删除缓存,后更新数据库
①同步更新缓存策略
A线程进行写操作,先成功淘汰缓存,但由于网络或其它原因,还未更新数据库或正在更新
B线程进行读操作,发现缓存中没有想要的数据,从数据库中读取数据,但此时A线程还未完成更新操作,所以读取到的是旧数据,并且B线程将旧数据放入缓存。注意此时是没有问题的,因为数据库中的数据还未完成更新,所以数据库与缓存此时存储的都是旧值,数据没有不一致
在B线程将旧数据读入缓存后,A线程终于将数据更新完成,此时是有问题的,数据库中是更新后的新数据,缓存中是更新前的旧数据,数据不一致。如果在缓存中没有对该值设置过期时间,旧数据将一直保存在缓存中,数据将一直不一致,直到之后再次对该值进行修改时才会在缓存中淘汰该值
此时可能会导致cache与数据库的数据一直或很长时间不一致
# 解决方案一:使用串行化思路
即保证对同一个数据的读写严格按照先后顺序串行化进行,避免并发较大的情况下,多个线程同时对同一数据进行操作时带来的数据不一致性。
# 解决方案二:延时双删+设置缓存的超时时间
不一致的原因是,在淘汰缓存之后,旧数据再次被读入缓存,且之后没有淘汰策略,所以解决思路就是,在旧数据再次读入缓存后,再次淘汰缓存,即淘汰缓存两次(延迟双删)
引入延时双删后,执行步骤变为下面这种情形:
A线程进行写操作,先成功淘汰缓存,但由于网络或其它原因,还未更新数据库或正在更新
B线程进行读操作,从数据库中读入旧数据,共耗时N秒
在B线程将旧数据读入缓存后,A线程将数据更新完成,此时数据不一致
A线程将数据库更新完成后,休眠M秒(M比N稍大即可),然后再次淘汰缓存,此时缓存中即使有旧数据也会被淘汰,此时可以保证数据的一致性
其它线程进行读操作时,缓存中无数据,从数据库中读取的是更新后的新数据
引入延时双删后,存在两个新问题:
A线程需要在更新数据库后,还要休眠M秒再次淘汰缓存,等所有操作都执行完,这一个更新操作才真正完成,降低了更新操作的吞吐量
解决办法:用“异步淘汰”的策略,将休眠M秒以及二次淘汰放在另一个线程中,A线程在更新完数据库后,可以直接返回成功而不用等待。
如果第二次缓存淘汰失败,则不一致依旧会存在
解决办法:用“重试机制”,即当二次淘汰失败后,报错并继续重试,直到执行成功个人
“异步淘汰”策略:
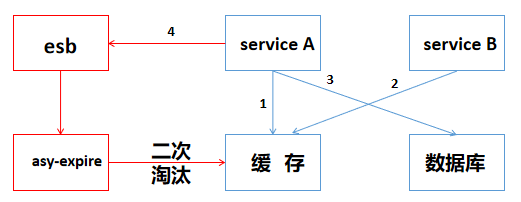
A线程执行完步骤2不再休眠Ms,而是往消息总线esb发送一个消息,发送完成之后马上就能返回
②异步更新缓存策略:
- A线程进行写操作,先成功淘汰缓存,但由于网络或其它原因,还未更新数据库或正在更新
- B线程进行读操作,发现缓存中没有想要的数据,从数据库中读取数据,但B线程只是从数据库中读取想要的数据,并不将这个数据放入缓存中,所以并不会导致缓存与数据库的不一致
- A线程更新数据库后,通过订阅binlog来异步更新缓存
- 此时数据库与缓存的内容将一直都是一致的
# 先更新数据库,后删除缓存
问题:这一种情况也会出现问题,比如更新数据库成功了,但是在删除缓存的阶段出错了没有删除成功,那么此时再读取缓存的时候每次都是错误的数据了。
# 解决方案一:使用消息队列
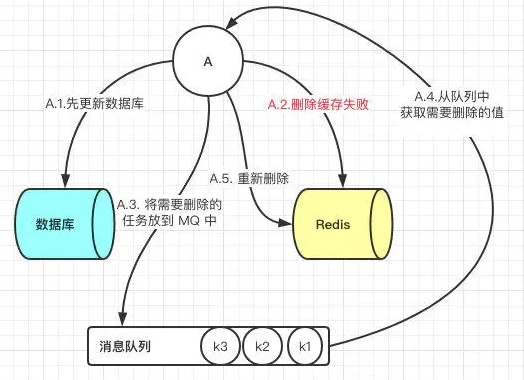
此时解决方案就是**利用消息队列进行删除(重试机制)**的补偿。具体的业务逻辑用语言描述如下:
- 请求 A 先对数据库进行更新操作
- 在对 Redis 进行删除操作的时候发现报错,删除失败
- 此时将Redis 的 key 作为消息体发送到消息队列中
- 系统接收到消息队列发送的消息后再次对 Redis 进行删除操作
但是这个方案会有一个缺点就是会对业务代码造成大量的侵入,深深的耦合在一起,所以这时会有一个优化的方案,我们知道对 Mysql 数据库更新操作后再 binlog 日志中我们都能够找到相应的操作,那么我们可以订阅 Mysql 数据库的 binlog 日志对缓存进行操作。
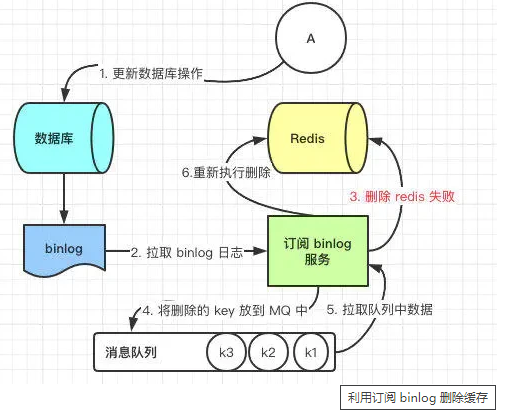
# 解决方案二:延时双删
依旧是先更新数据库,再删除缓存,唯一不同的是,我们把这个删除的动作,在不久之后再执行一次,比如 5s 之后。
# 总结
每种方案各有利弊,比如在第二种先删除缓存,后更新数据库这个方案我们最后讨论了要更新 Redis 的时候强制走主库查询就能解决问题,那么这样的操作会对业务代码进行大量的侵入,但是不需要增加的系统,不需要增加整体的服务的复杂度。
最后一种方案我们最后讨论了利用订阅 binlog 日志进行搭建独立系统操作 Redis,这样的缺点其实就是增加了系统复杂度。其实每一次的选择都需要我们对于我们的业务进行评估来选择,没有一种技术是对于所有业务都通用的。没有最好的,只有最适合我们的。
两种方案的比较:
先淘汰cache,再更新数据库:**
- 采用同步更新缓存的策略,可能会导致数据长时间不一致,如果用延迟双删来优化,还需要考虑究竟需要延时多长时间的问题——读的效率较高,但数据的一致性需要靠其它手段来保证
- 采用异步更新缓存的策略,不会导致数据不一致,但在数据库更新完成之前,都需要到数据库层面去读取数据,读的效率不太好——保证了数据的一致性,适用于对一致性要求高的业务
先更新数据库,再淘汰cache:
- 无论是同步/异步更新缓存,都不会导致数据的最终不一致,在更新数据库期间,cache中的旧数据会被读取,可能会有一段时间的数据不一致,但读的效率很好——保证了数据读取的效率,如果业务对一致性要求不是很高,这种方案最合适
# Spring缓存机制与Redis
