存储引擎分类
# 存储引擎定义
现代数据库大体可以分为三层。最上层用于连接、线程处理等;中间层提供数据库的核心功能,包括 SQL 解析、分析、优化、视图等;底层就是数据库的存储引擎,负责数据的存储与提取。
简单来说,存储引擎是为数据库提供创建、查询、更新、存储数据的软件模块。不同的存储引擎的主要区别是数据的存储方式,此外功能、特性、速度等也有所差异。
存储引擎为数据库屏蔽了底层存储的细节。现在许多数据库管理系统都支持多种存储引擎,通过插件化的方式配置。可以根据具体场景,选择不同的存储引擎。
# MySQL 支持的存储引擎
在 MySQL 中执行 SHOW ENGINES;,可以看到支持的存储引擎列表,不同环境下可能有一定差异: 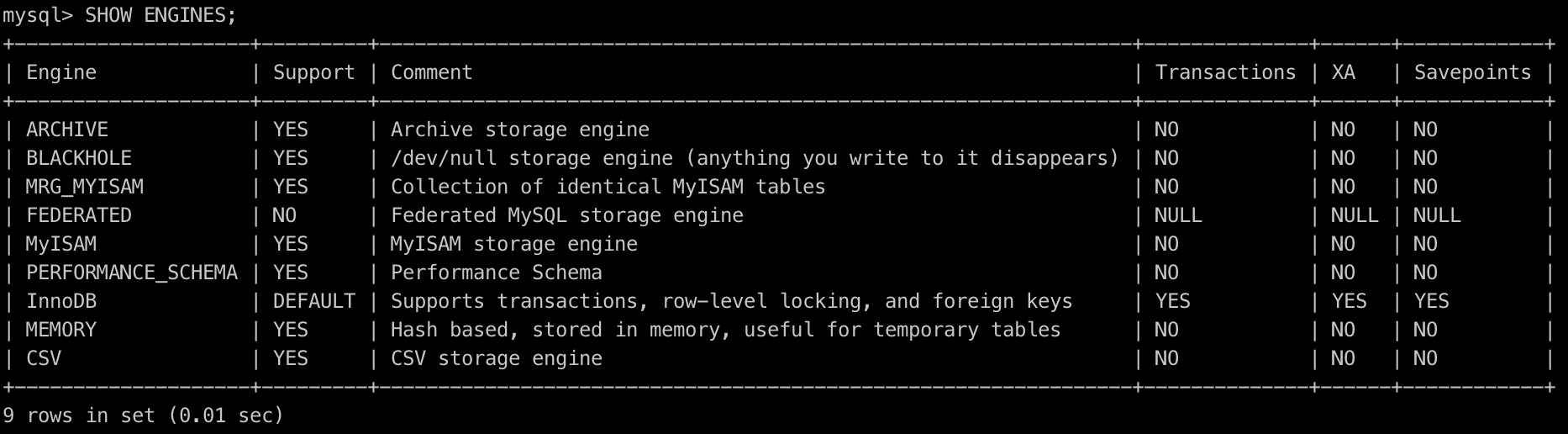
MySQL 的存储引擎主要分为两大类:事务型、非事务型,从上图中的“Transactions”一列可以看出来,只有 InnoDB 引擎支持事务。
在 MySQL 5.5 及之后的版本中,默认的存储引擎是 InnoDB,而在这之前是 MyISAM。
# 不同的存储引擎简介
- InnoDB
- MyISAM
- Memory
- CSV
- Merge
- Archive
- Blackhole
- Federated
- Example
InnoDB 是最广泛使用的存储引擎。支持事务,满足 ACID 约束。支持行级锁,崩溃恢复和多版本并发控制(MVCC)。是唯一支持外键引用完整性约束的存储引擎。
MyISAM 是一个很快的存储引擎。不支持事务。只支持表级锁。常用在 Web 和数据仓库中。
Memory 将数据表创建在内存中,是最快的存储引擎。不支持事务,支持表级锁。Memory 存储引擎很适合于创建临时表或者快速查询的场景。当数据库重启时,内存中的数据会丢失。
CSV 将数据存储为 CSV 格式的文件。CSV 是一种通用的、相对简单的文件格式,可以很方便的被其他应用(如 Excel)读取。
Merge 在新版 MySQL 中称为 MRG_MyISAM,它将一组相似的 MyISAM 表组合起来,视作一个表。Merge 表本身没有数据,实际是在操作底层的 MyISAM 表。Merge 存储引擎能够更简单的管理大量数据,适用于数据仓库(如服务器日志)等场景。
Archive 存储引擎针对高速插入进行了优化。它会将插入的数据实时压缩。不支持事务。由于数据被压缩,因此仅支持插入和查询两种功能。适用于用作仓库,存储大量归档数据。
Blackhole(黑洞)存储引擎接受但不存储任何数据(类似于 Linux 中的 /dev/null),查询时永远返回空集。该存储引擎可用于执行性能测试。
Federated(联合)存储引擎可以将多台物理服务器创建为一个逻辑数据库,数据存储在远程服务器中,本地不存储数据。本地服务器上的查询将在远程(联合)表上自动执行。适用于分布式场景。
Example 可以创建表,但不能存储或获取数据,可以用来学习如何编写新的存储引擎。
# InnoDB、MyISAM、Memory 详解
# InnoDB
# 特性
| 特性 | 是否支持 | 特性 | 是否支持 |
|---|---|---|---|
| 多版本并发控制(MVCC) | Yes | 锁机制(Locking granularity) | 行级锁 |
| 事务(Transactions) | Yes | 外键支持(Foreign key support) | Yes |
| 索引(Indexes) | Yes | 热备份/灾难恢复 | Yes |
# 存储结构
InnoDB 将表结构存储在 .frm 文件中,数据和索引存储在 .idb 文件中。.idb 文件是由 InnoDB 管理的特殊格式的数据文件,表示每一个表独有的表空间(tablespace)。
在表空间中,所有的数据记录都被逻辑地存放在表空间中。表空间被进一步划分为段(segment)、区(extent)、页(page)。页是 InnoDB 管理数据的最小磁盘单位,每个 16KB 大小的页中可以存放 2-200 行的记录。
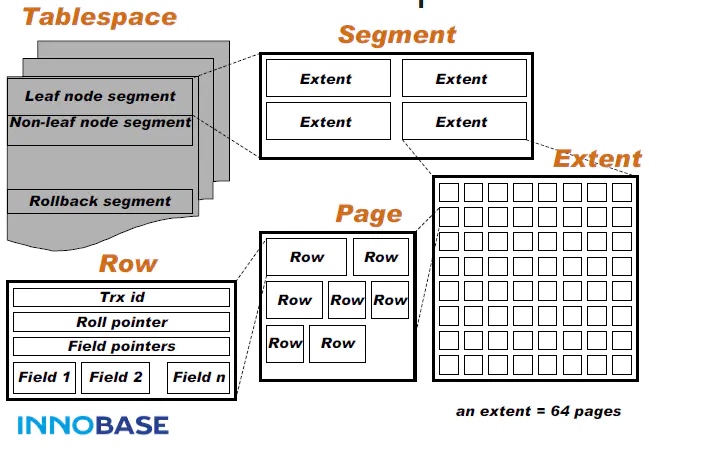
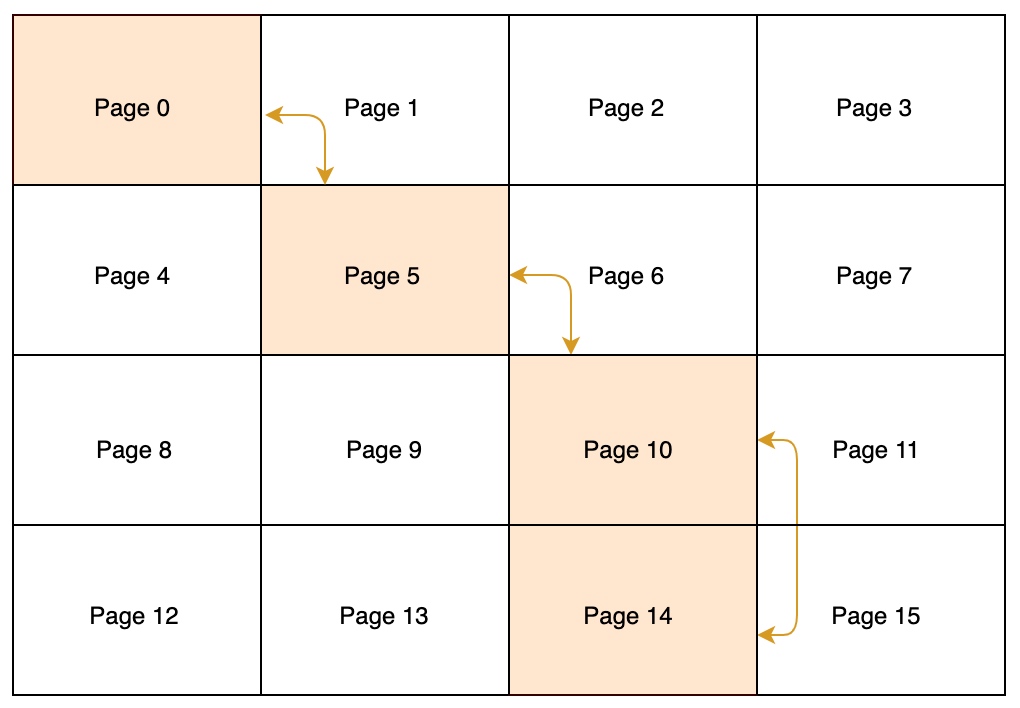
InnoDB 的行记录在物理存储上并不是顺序的。为了保证插入和删除的效率,整个页面并不会按照主键顺序对行记录进行排序,而是自动从左向右寻找空白节点进行插入,通过行记录中的 next_record 指针表示它们之间的逻辑顺序。
InnoDB 在查找某条记录时,并不能直接找到对应的行记录,而是只能获取到记录所在的页,然后将整个页面加载到内存中,在内存中遍历找到具体行。这部分耗时一般可以忽略。
InnoDB 的行记录并不是物理上连续的,主要有两方面原因:
- B+ 树上相邻的叶节点并不一定是磁盘上相邻的页面
- 同一个页面中的行记录也不一定是按照主键顺序排列的
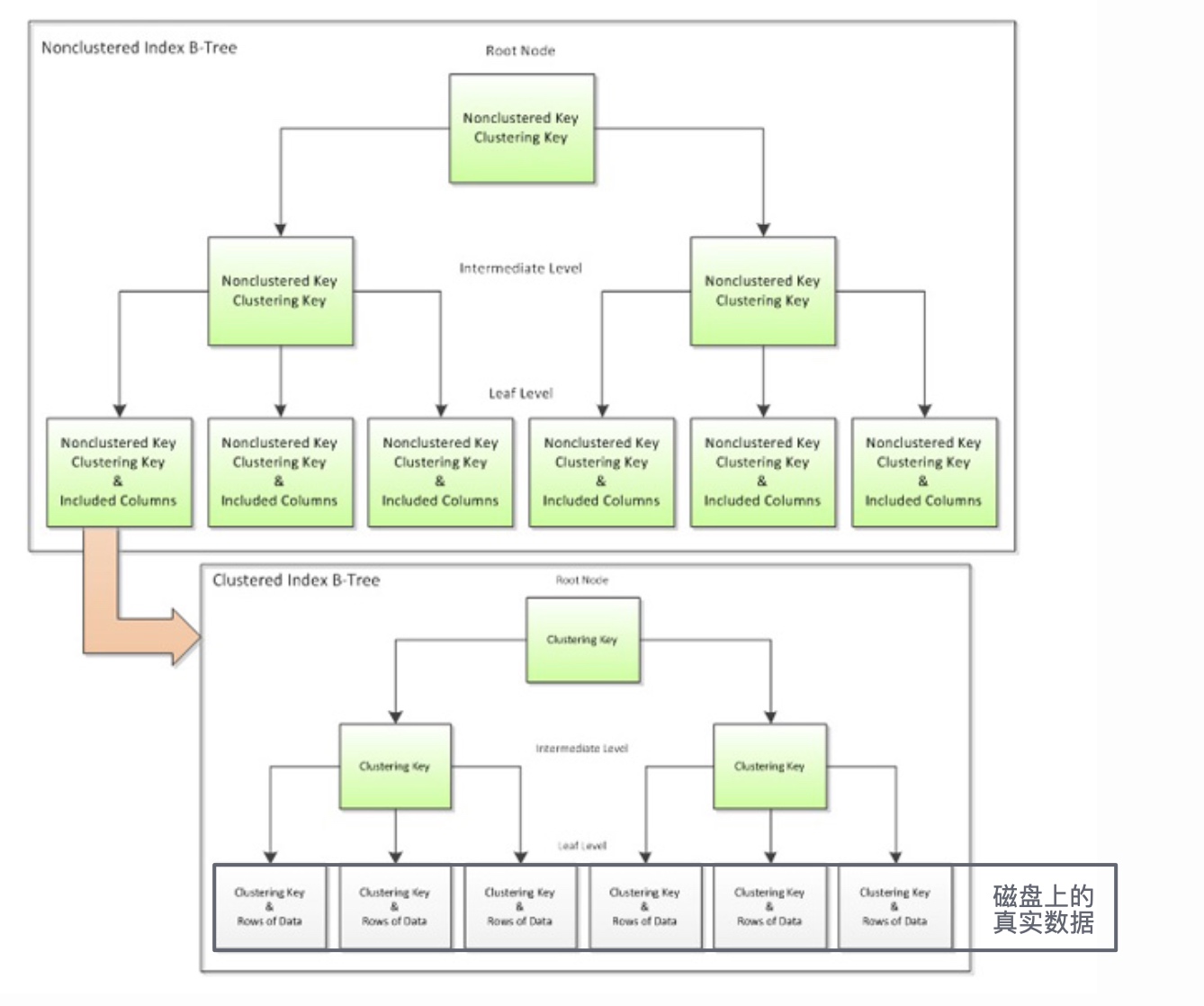
# 聚集索引与非聚集索引
InnoDB 存储引擎的数据存储方式是聚集索引。InnoDB 的每个表有且仅有一个聚集索引。InnoDB 默认会使用每个表的主键顺序,为表格中所有行记录构建一棵 B+ 树,其叶节点以页面为单位,存放完整的行记录,所有叶节点存放了整张表的数据。
这些 B+ 树的叶节点,就是上文的“数据页”。相邻编号的页,在物理上是相邻的,但不一定是 B+ 树的相邻的叶节点。B+ 树的每个非叶节点,也分别保存在一个数据页中。数据页的大小默认与操作系统的页面大小是相同的,都是 16KB。
关于 InnoDB 中记录的格式,可以阅读:
非聚集索引也称为辅助索引。非聚集索引同样是一棵 B+ 树,但是叶节点仅存储索引列的所有键,和对应行记录的主键。
当通过非聚集索引查找一条行记录时,需要先通过非聚集索引查找到对应的主键,然后在聚集索引中根据主键二次查找,获取到对应的行记录。
聚集索引与非聚集索引的关系(图源 (opens new window)):
# 优缺点、适用场景
- 支持事务、行锁、外键、MVCC 等特性
- 并发能力较好,适用于更新密集的场景。这是因为在更新数据时,InnoDB 使用的是行锁,粒度小,竞争情况少,从而增加增加了并发处理(插入数据时使用的是表锁)
- 读写效率较差。主要原因在于索引查询后还需要根据主键进行二次查找
- 占用空间大
大多数场景下都可以选择 InnoDB 引擎,InnoDB 也是 MySQL 的默认存储引擎。
# MyISAM
MyISAM 基于旧的 ISAM 存储引擎,增加了许多有用的扩展。
# 特性
| 特性 | 是否支持 | 特性 | 是否支持 |
|---|---|---|---|
| 索引(Indexes) | Yes | 锁机制(Locking granularity) | 表级锁 |
# 存储结构
每个 MyISAM 表格会保存在磁盘的三个文件中,文件名就是表名:
.frm:存储表结构.MYD(MYData):存储数据.MYI(MYIndex):存储索引
不同于 InnoDB,MyISAM 的数据是顺序存储的。索引的 B+ 树叶节点存放数据记录的地址,可以直接定位到数据,因此查找速度很快(图源 (opens new window)):
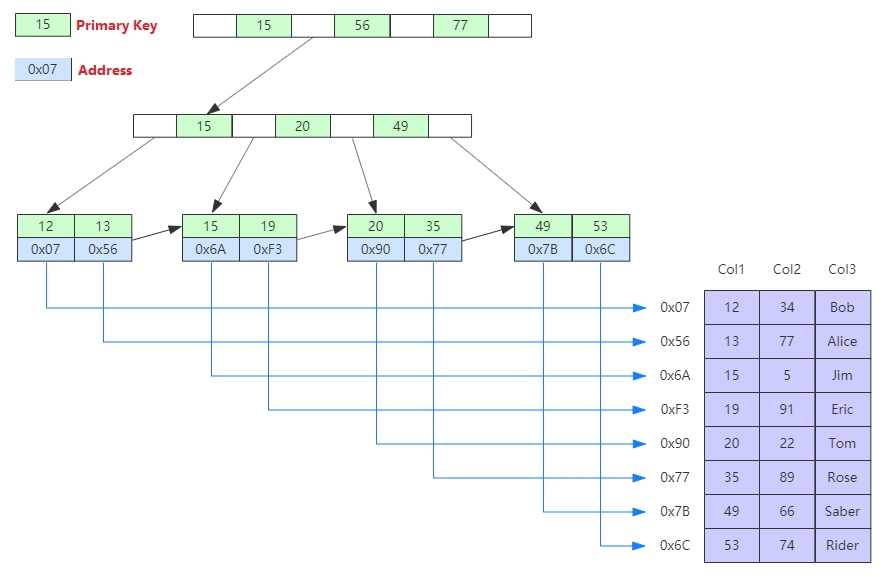
# 优缺点、适用场景
- 占用空间小
- 处理速度快,适用于选择(select)密集的场景。这是因为可以通过索引节点直接定位到数据,不需要二次查找
- 支持全文索引(InnoDB 也支持)
- 不支持事务
- 只支持表级锁(为了并发插入)
适用于包含大量读取操作(read-heavy)、不需要事务支持的场景,效率很高,例如数据仓库和 Web 应用程序。
# Memory
# 简介
| 特性 | 是否支持 | 特性 | 是否支持 |
|---|---|---|---|
| 索引(Indexes) | Yes | 锁机制(Locking granularity) | 表级锁 |
Memory 存储引擎,顾名思义,将数据存在系统内存里,因此读写速度快,性能高。但是安全性不高,数据可能因为进程崩溃或硬件重启而丢失。
Memory 中的每个表对应磁盘上的一个 .frm 文件,该文件只存储表结构,数据都存储在内存中。
# 适用场景
- 需要很快的读写速度
- 数据库表相对较小(内存空间有限)
- 对数据的安全性要求较低
以上是“且”的关系。不过一般很少使用 Memory 存储引擎。
# 综合对比
| 特性 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| 事务(Transactions) | ✔️ | ✖️ | ✖️ |
| 外键支持(Foreign key support) | ✔️ | ✖️ | ✖️ |
| 锁机制(Locking granularity) | 行级锁 | 表级锁 | 表级锁 |
| 多版本并发控制(MVCC) | ✔️ | ✖️ | ✖️ |
| B树索引(B-tree indexes) | ✔️ | ✔️ | ✔️ |
| 哈希索引(Hash indexes) | ✖️ | ✖️ | ✔️ |
| 全文索引(Full-text indexes) | ✔️ | ✔️ | ✖️ |
| 空间使用 | 高 | 低 | N/A |
| 查询速度 | 低 | 高 | 高 |
| 插入速度 | 低 | 高 | 高 |
# 如何选择存储引擎
每个存储引擎在功能和限制上都有差异。在某些情况下,只能选择特定的存储引擎,比如需要支持事务、热备份、崩溃恢复、外键支持、缓存等,或者不能有存储限制。在其他情况下,可以灵活选择不同的存储引擎:
- 同一个数据库的不同表,可以使用不同的存储引擎。比如查询密集的表可以使用 MyISAM,用于查询的临时表可以使用 Memory
- 不同服务器上的数据库,也可以使用不同的存储引擎。比如读写分离的场景下,从数据库可以使用 MyISAM,提高查询速度