物理内存管理
# 概述
32位机器上的每个Linux进程通常有3GB的虚拟地址空间,还有1GB留给其页表和其他内核数据。在用户态下运行时,内核的1GB是不可见的,但是当进程陷入到内核时是可以访问的。==内核内存通常驻留在低端物理内存中,但是被映射到每个进程虚拟地址空间顶部的1GB中,在地址0xC0000000和0xFFFFFFFF(3~4GB)之间==。当进程创建的时候,进程地址空间被创建,并且当发生一个exec系统调用时被重写。
为了允许多个进程共享物理内存,Linux监视物理内存的使用,在用户进程或者内核构件需要时分配更多的内存,把物理内存动态映射到不同进程的地址空间中去,把程序的可执行体、文件和其他状态信息移入移出内存来高效地利用平台资源并且保障程序执行的进展性。
Linux 把物理内存划分为三个层次来管理: 存储节点(Node)、内存管理区(Zone)和页面(Page)
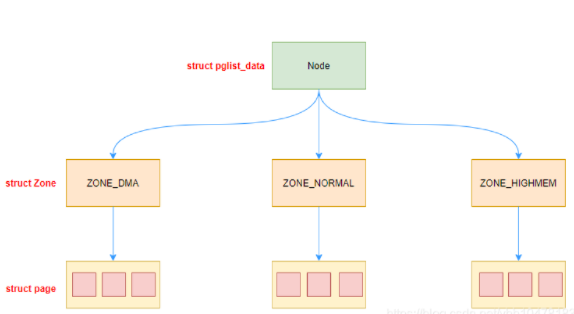
现在有一个问题:
为什么linux描述物理内存需要划分这么多层次?
# Nodes
# 为什么需要Node?
在回答这个问题之前, 我们需要先了解计算机系统中的两个内存架构: UMA 和 NUMA。
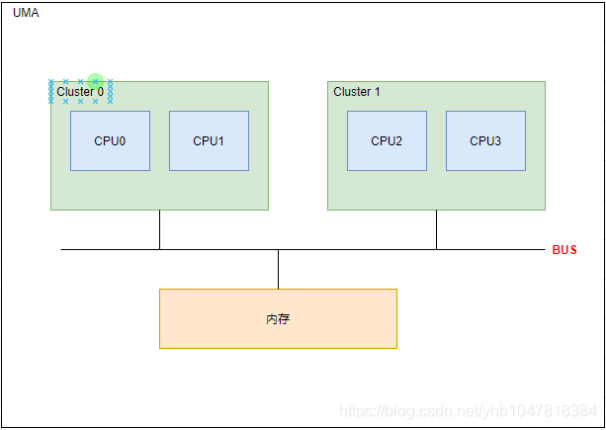
UMA: Uniform Memory Access, 统一内存访问。每个CPU共享相同的内存地址空间。目前UMA架构广泛应用于嵌入式系统、手机以及个人电脑等。
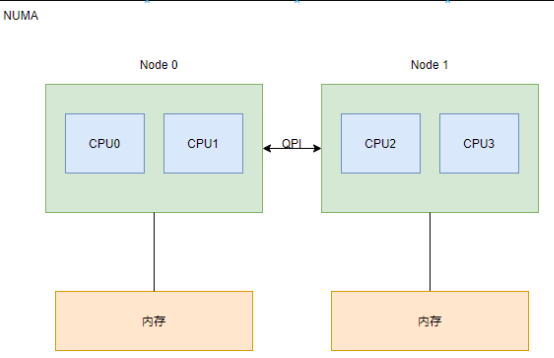
NUMA: Non-Uniform Memory Access, 非统一内存访问。系统中会有很多的内存节点和多个CPU簇, 所有节点中的CPU可以访问全部的物理内存,但是CPU访问本地的节点速度远快于访问远端的内存节点的速度。目前NUMA架构广泛应用于大型的硬件平台,如服务器。
NUMA架构最主要的目的是提供可扩展的内存带宽。为了兼容这一设计,linux将系统的硬件资源分成称为“Node”的多个软件抽象。如上图所示,CPU0和CPU1组成一个节点(Node 0), 它们可以通过系统总线访问本地的L3 cache和内存, I/O总线等资源。对于UMA架构而言,内核可以把内存当成只有一个内存node节点。
==Linux内存架构分为UMA(统一内存访问)和NUMA(非统一内存访问),UMA可以看成是一个节点的NUMA。NUMA是因为物理内存组织是分布式的,每个cpu有自己的本地内存,可以快速访问本地内存,可以通过总线进行访问其它cpu的本地内存。==
# pglist_data数据结构
node的数据结构为pglist_data, 每一个node对应一个struct pglist_data.
struct pglist_data *node_data[MAX_NUMNODES] __read_mostly;
pg_data_t的数据结构:
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES];
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones;
unsigned long node_start_pfn;
unsigned long node_present_pages;
unsigned long node_spanned_pages;
int node_id;
wait_queue_head_t kswapd_wait;
wait_queue_head_t pfmemalloc_wait;
struct task_struct *kswapd;
int kswapd_order;
enum zone_type kswapd_highest_zoneidx;
int kswapd_failures;
unsigned long min_unmapped_pages;
unsigned long min_slab_pages;
ZONE_PADDING(_pad1_)
spinlock_t lru_lock;
struct deferred_split deferred_split_queue;
struct lruvec __lruvec;
unsigned long flags;
ZONE_PADDING(_pad2_)
struct per_cpu_nodestat __percpu *per_cpu_nodestats;
atomic_long_t vm_stat[NR_VM_NODE_STAT_ITEMS];
} pg_data_t;
关键的数据成员:
| 属性 | 描述 |
|---|---|
| node_zones[MAX_NR_ZONES] | 对应该node包含的各个类型的zone |
| node_zonelists | 包含了2个zonelist,自身node的zones列表以及备用的zones列表(用于本地node分配不到内存时的备选,也称为fallback) |
| nr_zones | 包含zone的个数 |
| node_start_pfn | 该node中内存的起始页帧号 |
| node_present_pages | 该node地址范围内的实际管理的页面数量 |
| node_spanned_pages | 该node地址范围内的所有页面数量, 包括空洞的页面 |
| kswapd | 负责回收该node内存的内核线程,每个node对应一个内核线程kswapd |
| lru_lock | 用于保护Zone中lru链表的锁 |
| lruvec | LRU链表的集合 |
| flags | 内存域的当前状态, 在mmzone.h定义了zone的所有可用zone_flag |
| vm_stat | node的计数 |
ZONE_PADDING宏作用是让前后的成员分布在不同的cache line中, 以空间换取时间。
在linux环境中我们可以使用numactl命令查看Node中的cpu和内存,以及各个node之间的distance
numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 16 17 18 19 20 21 22 23
node 0 size: 131037 MB
node 0 free: 3019 MB
node 1 cpus: 8 9 10 11 12 13 14 15 24 25 26 27 28 29 30 31
node 1 size: 131071 MB
node 1 free: 9799 MB
node distances:
node 0 1
0: 10 20
1: 20 10
# Zones
# 为什么需要将node拆分成不同的zone
其实这是个历史遗留问题,出于对不同架构的兼容性的考虑。
比如32位的处理器只支持4G的虚拟地址,然后1G的地址空间给内核,但这样无法对超过1个G的物理内存进行一一映射。 Linux内核提出的解决方案是将物理内存分成2部分,一部分直接做线性映射,另一部分叫高端内存。这两部分对应内存管理 (opens new window)区就分别为ZONE_NORMAL和ZONE_HIGNMEM。 当然对于64位的架构而言,有足够大的内核地址空间可以映射物理内存,所以就不需要ZONE_HIGHMEM了。
所以,将node拆分成zone主要还是出于Linux为了兼容各种架构和平台,对不同区域的内存需要采用不同的管理方式和映射方式。
由于硬件的限制,内核对不同的page frame采用不同的处理方法,将相同属性的page frame归到一个zone中,主要分为DMA、Normal和Highmem,==切记zone是对物理地址的划分,不是对虚拟地址的划分。==
- DMA可以直接在内存和外设之间进行数据的读写,不需要cpu的直接参与。由于硬件的限制,DMA并不是可以访问所有的内存,实际只可以访问16M一下的内存。
- Highmem:适用于要访问的物理内存地址空间大于虚拟地址空间的,不能直接建立直接映射场景的高端内存。
- normal:除开dma和highmem的物理内存。
# Zone type
linux内存管理区可以分为如下几种:[include/linux/mmzone.h]
enum zone_type {
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};
| zone type | descrpition |
|---|---|
| ZONE_DMA | ISA设备的DMA操作,范围是0~16M,ARM架构没有这个zone |
| ZONE_DMA32 | 用于低于4G内存进行DMA操作的32位设备 |
| ZONE_NORMAL | 标记了线性映射物理内存, 4G以上的物理内存。 如果系统内存不足4G, 那么所有的内存都属于ZONE_DMA32范围, ZONE_NORMAL则为空 |
| ZONE_HIGHMEM | 高端内存,标记超出内核虚拟地址空间的物理内存段. 64位架构没有该ZONE |
| ZONE_MOVABLE | 虚拟内存域, 在防止物理内存碎片的机制中会使用到该内存区域 |
| ZONE_DEVICE | 为支持热插拔设备而分配的Non Volatile Memory非易失性内存 |
在linux环境中,我们可以通过下面命令查看Zone的分类
cat /proc/zoneinfo |grep Node
Node 0, zone DMA32
Node 0, zone Normal
Node 0, zone Movable
Node 1, zone DMA32
Node 1, zone Normal
Node 1, zone Movable
Node 2, zone DMA32
Node 2, zone Normal
Node 2, zone Movable
Node 3, zone DMA32
Node 3, zone Normal
Node 3, zone Movable
# zone的数据结构
zone的数据结构定义在[include/mm/mmzone.h]
struct zone {
unsigned long _watermark[NR_WMARK];
unsigned long watermark_boost;
unsigned long nr_reserved_highatomic;
long lowmem_reserve[MAX_NR_ZONES];
int node;
struct pglist_data *zone_pgdat;
struct per_cpu_pageset __percpu *pageset;
unsigned long *pageblock_flags;
int initialized;
ZONE_PADDING(_pad1_)
struct free_area free_area[MAX_ORDER];
unsigned long flags;
spinlock_t lock;
ZONE_PADDING(_pad2_)
unsigned long percpu_drift_mark;
bool contiguous;
ZONE_PADDING(_pad3_)
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
atomic_long_t vm_numa_stat[NR_VM_NUMA_STAT_ITEMS];
} ____cacheline_internodealigned_in_smp;
几个比较关键的数据成员:
| 属性 | 描述 |
|---|---|
| watermark | 水线, 在系统启动时会计算WMARK_MIN、WMARK_LOW、WMARK_HIGH, 在kswapd页面回收中和分配页面时会有用到 |
| lowmem_reserve | 本管理区预留的物理内存大小 |
| zone_pgdat | 指向所属的node节点 |
| pageset | 每个CPU维护一个page list,避免自旋锁的冲突 |
| free_area[MAX_ORDER] | 空闲内存链表,按2的幂次分组,用于实现伙伴系统 |
| lock | 对zone并发访问的保护的自旋锁 |
| vm_stat | zone的计数 |
# Pages
物理页面通常被称作Page Frames。 Linux内核使用struct page数据结构来描述一个物理页面, 这些page数据结构会存放在一个数组中。
struct page和物理页面是一对一的映射关系。
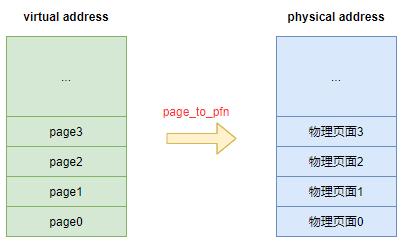
映射的关系取决于当前的内存模型, 当前内核支持3种内存模型FLATMEM、DISCONTIGMEM、SPARSEMEM。
关于内存模型,可以看wowotech的这篇文章【Linux内存模型 (opens new window)】
#if defined(CONFIG_FLATMEM)
#define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET))
#define __page_to_pfn(page) ((unsigned long)((page) - mem_map) + \
ARCH_PFN_OFFSET)
#elif defined(CONFIG_DISCONTIGMEM)
#define __pfn_to_page(pfn) \
({ unsigned long __pfn = (pfn); \
unsigned long __nid = arch_pfn_to_nid(__pfn); \
NODE_DATA(__nid)->node_mem_map + arch_local_page_offset(__pfn, __nid);\
})
#define __page_to_pfn(pg) \
({ const struct page *__pg = (pg); \
struct pglist_data *__pgdat = NODE_DATA(page_to_nid(__pg)); \
(unsigned long)(__pg - __pgdat->node_mem_map) + \
__pgdat->node_start_pfn; \
})
#elif defined(CONFIG_SPARSEMEM_VMEMMAP)
#define __pfn_to_page(pfn) (vmemmap + (pfn))
#define __page_to_pfn(page) (unsigned long)((page) - vmemmap)
#elif defined(CONFIG_SPARSEMEM)
#define __page_to_pfn(pg) \
({ const struct page *__pg = (pg); \
int __sec = page_to_section(__pg); \
(unsigned long)(__pg - __section_mem_map_addr(__nr_to_section(__sec))); \
})
#define __pfn_to_page(pfn) \
({ unsigned long __pfn = (pfn); \
struct mem_section *__sec = __pfn_to_section(__pfn); \
__section_mem_map_addr(__sec) + __pfn; \
})
#endif
# page的数据结构
struct page {
unsigned long flags;
union {
struct {
struct list_head lru;
struct address_space *mapping;
pgoff_t index;
unsigned long private;
};
struct {
dma_addr_t dma_addr;
};
struct
union {
struct list_head slab_list;
struct {
struct page *next;
int pages;
int pobjects;
};
};
struct kmem_cache *slab_cache;
void *freelist;
union {
void *s_mem;
unsigned long counters;
struct {
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
};
};
struct {
unsigned long compound_head;
unsigned char compound_dtor;
unsigned char compound_order;
atomic_t compound_mapcount;
unsigned int compound_nr;
};
struct {
unsigned long _compound_pad_1; /
atomic_t hpage_pinned_refcount;
struct list_head deferred_list;
};
struct {
unsigned long _pt_pad_1;
pgtable_t pmd_huge_pte;
unsigned long _pt_pad_2;
union {
struct mm_struct *pt_mm;
atomic_t pt_frag_refcount;
};
spinlock_t ptl;
};
struct {
struct dev_pagemap *pgmap;
void *zone_device_data;
};
struct rcu_head rcu_head;
};
union {
atomic_t _mapcount;
unsigned int page_type;
unsigned int active;
int units;
};
atomic_t _refcount;
#ifdef CONFIG_MEMCG
union {
struct mem_cgroup *mem_cgroup;
struct obj_cgroup **obj_cgroups;
};
#endif
...
} _struct_page_alignment;
重要的数据成员:
| 属性 | 描述 |
|---|---|
| flags | 用于描述page的状态或者其他属性, 每一bit代表一种状态;在 include/linux/page_flags.h定义有page的各个可用状态pageflags |
| mapping | mapping指定了页帧所在的地址空间。有三种含义:mapping = 0,说明该page属于swap cache; mapping != 0,bit[0] = 0,说明该page属于页缓存或文件映射,mapping指向文件的地址空间address_space; mapping != 0,bit[0] != 0,说明该page为匿名映射,mapping指向struct anon_vma对象 |
| index | index是页帧在映射内部的偏移量, 即在映射的虚拟空间(vma_area)内的偏移 |
| private | 私有数据指针,由应用场景确定其具体的含义 |
| _mapcount | 被页表映射的次数,也就是说该page同时被多少个进程共享.(注意:被映射了不一定在使用, 需要和下面的refcount进行区分) |
| _refcount | 表示引用计数。当count值为0时,该page frame可被free掉;如果不为0,说明该page正在被某个进程或者内核使用,调用page_count()可获得count值。 |