文件系统基础
# 文件系统布局

文件系统存放在磁盘上。多数磁盘划分为一个或多个分区,每个分区中有一个独立的文件系统。磁盘的0号扇区称为主引导记录(Master Boot Record,MBR),用来引导计算机。
在MBR的结尾是分区表。该表给出了每个分区的起始和结束地址。表中的一个分区被标记为活动分区。==在计算机被引导时,BIOS读入并执行MBR。MBR做的第一件事是确定活动分区,读入它的第一个块,称为引导块(boot block),并执行之。==
引导块中的程序将装载该分区中的操作系统。为统一起见,每个分区都从一个启动块开始,即使它不含有一个可启动的操作系统。不过,在将来这个分区也许会有一个操作系统的。
除了从引导块开始之外,磁盘分区的布局是随着文件系统的不同而变化的。文件系统经常包含有如图4-9所列的一些项目。第一个是超级块(superblock),超级块包含文件系统的所有关键参数,在计算机启动时,或者在该文件系统首次使用时,把超级块读入内存。超级块中的典型信息包括:确定文件系统类型用的魔数、文件系统中数据块的数量以及其他重要的管理信息。
接着是文件系统中空闲块的信息,例如,可以用位图或指针列表的形式给出。后面也许跟随的是一组i节点,这是一个数据结构数组,每个文件一个,i节点说明了文件的方方面面。接着可能是根目录,它存放文件系统目录树的根部。最后,磁盘的其他部分存放了其他所有的目录和文件。
# 什么是 inode ?
一般来说,面试不会问 inode 。但是 inode 是一个重要概念,是理解 Unix/Linux 文件系统和硬盘储存的基础。
理解inode,要从文件储存说起。
文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(Sector)。每个扇区储存512字节(相当于0.5KB)。
操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"(block)。这种由多个扇区组成的"块",是文件存取的最小单位。"块"的大小,最常见的是4KB,即连续八个 sector组成一个 block。
文件数据都储存在"块"中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。
每一个文件都有对应的inode,里面包含了与该文件有关的一些信息。
# 简述 Linux 文件系统通过 i 节点把文件的逻辑结构和物理结构转换的工作过程?
Linux 通过 inode 节点表将文件的逻辑结构和物理结构进行转换。
inode 节点是一个 64 字节长的表,表中包含了文件的相关信息,其中有文件的大小、文件所有者、文件的存取许可方式以及文件的类型等重要信息。在 inode 节点表中最重要的内容是磁盘地址表。在磁盘地址表中有 13 个块号,文件将以块号在磁盘地址表中出现的顺序依次读取相应的块。
Linux 文件系统通过把 inode 节点和文件名进行连接,当需要读取该文件时,文件系统在当前目录表中查找该文件名对应的项,由此得到该文件相对应的 inode 节点号,通过该 inode 节点的磁盘地址表把分散存放的文件物理块连接成文件的逻辑结构。
# 什么是硬链接和软链接?
参考:[[硬链接与软链接]]
1)硬链接
由于 Linux 下的文件是通过索引节点(inode)来识别文件,硬链接可以认为是一个指针,==指向文件索引节点的指针==,系统并不为它重新分配 inode 。每添加一个一个硬链接,文件的链接数就加 1 。
不足:1)不可以在不同文件系统的文件间建立链接;2)只有超级用户才可以为目录创建硬链接。
2)软链接
软链接克服了硬链接的不足,没有任何文件系统的限制,任何用户可以创建指向目录的符号链接。因而现在更为广泛使用,它具有更大的灵活性,甚至可以跨越不同机器、不同网络对文件进行链接。
不足:因为链接文件包含有原文件的路径信息,所以当原文件从一个目录下移到其他目录中,再访问链接文件,系统就找不到了,而硬链接就没有这个缺陷,你想怎么移就怎么移;还有它要系统分配额外的空间用于建立新的索引节点和保存原文件的路径。
实际场景下,基本是使用软链接。总结区别如下:
- 硬链接不可以跨分区,软件链可以跨分区。
- 硬链接指向一个 inode 节点,而软链接则是创建一个新的 inode 节点。
- 删除软链接不一定会删除源文件;且删除硬链接不一定删除源文件,因为只有当索引结点中的链接数 = 0时,才会删除源文件。
# 虚拟文件系统
文件系统的种类众多,而操作系统希望对用户提供一个统一的接口,于是在用户层与文件系统层引入了中间层,这个中间层就称为虚拟文件系统(Virtual File System,VFS)。
VFS 定义了一组所有文件系统都支持的数据结构和标准接口,这样程序员不需要了解文件系统的工作原理,只需要了解 VFS 提供的统一接口即可。
在 Linux 文件系统中,用户空间、系统调用、虚拟机文件系统、缓存、文件系统以及存储之间的关系如下图:
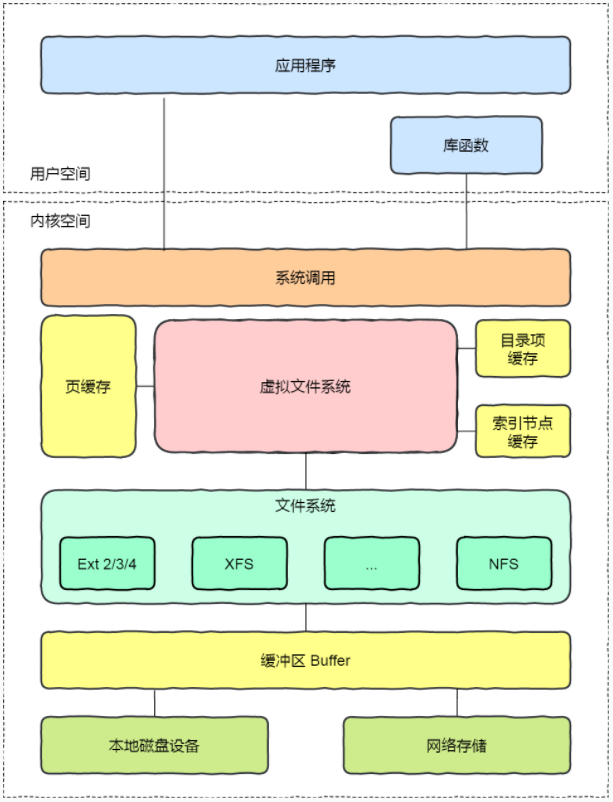
Linux 支持的文件系统也不少,根据存储位置的不同,可以把文件系统分为三类:
磁盘的文件系统,它是直接把数据存储在磁盘中,比如 Ext 2/3/4、XFS 等都是这类文件系统。
内存的文件系统,这类文件系统的数据不是存储在硬盘的,而是占用内存空间,我们经常用到的
/proc和/sys文件系统都属于这一类,读写这类文件,实际上是读写内核中相关的数据数据。网络的文件系统,用来访问其他计算机主机数据的文件系统,比如 NFS、SMB 等等。
文件系统首先要先挂载到某个目录才可以正常使用,比如 Linux 系统在启动时,会把文件系统挂载到根目录。
# 文件的使用
我们从用户角度来看文件的话,就是我们要怎么使用文件?首先,我们得通过系统调用来打开一个文件。

fd = open(name, flag);
# 打开文件...
write(fd,...);
# 写数据...
close(fd);
# 关闭文件
上面简单的代码是读取一个文件的过程:
首先用
open系统调用打开文件,open的参数中包含文件的路径名和文件名。使用
write写数据,其中write使用open所返回的文件描述符,并不使用文件名作为参数。使用完文件后,要用
close系统调用关闭文件,避免资源的泄露。
我们打开了一个文件后,操作系统会跟踪进程打开的所有文件,所谓的跟踪呢,就是==操作系统为每个进程维护一个打开文件表,文件表里的每一项代表「文件描述符」,所以说文件描述符是打开文件的标识==。
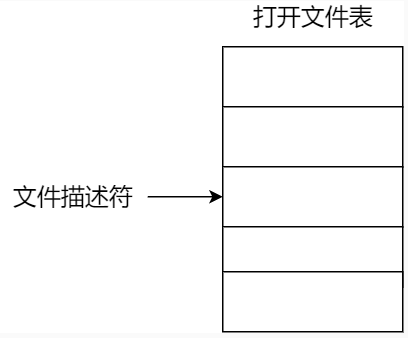
打开文件表
操作系统在打开文件表中维护着打开文件的状态和信息:
文件指针:系统跟踪上次读写位置作为当前文件位置指针,这种指针对打开文件的某个进程来说是唯一的;
文件打开计数器:文件关闭时,操作系统必须重用其打开文件表条目,否则表内空间不够用。因为多个进程可能打开同一个文件,所以系统在删除打开文件条目之前,必须等待最后一个进程关闭文件,该计数器跟踪打开和关闭的数量,当该计数为 0 时,系统关闭文件,删除该条目;
文件磁盘位置:绝大多数文件操作都要求系统修改文件数据,该信息保存在内存中,以免每个操作都从磁盘中读取;
访问权限:每个进程打开文件都需要有一个访问模式(创建、只读、读写、添加等),该信息保存在进程的打开文件表中,以便操作系统能允许或拒绝之后的 I/O 请求;
在用户视角里,文件就是一个持久化的数据结构,但操作系统并不会关心你想存在磁盘上的任何的数据结构,操作系统的视角是如何把文件数据和磁盘块对应起来。
所以,用户和操作系统对文件的读写操作是有差异的,用户习惯以字节的方式读写文件,而操作系统则是以数据块来读写文件,那屏蔽掉这种差异的工作就是文件系统了。
我们来分别看一下,读文件和写文件的过程:
当用户进程从文件读取 1 个字节大小的数据时,文件系统则需要获取字节所在的数据块,再返回数据块对应的用户进程所需的数据部分。
当用户进程把 1 个字节大小的数据写进文件时,文件系统则找到需要写入数据的数据块的位置,然后修改数据块中对应的部分,最后再把数据块写回磁盘。
所以说,文件系统的基本操作单位是数据块。